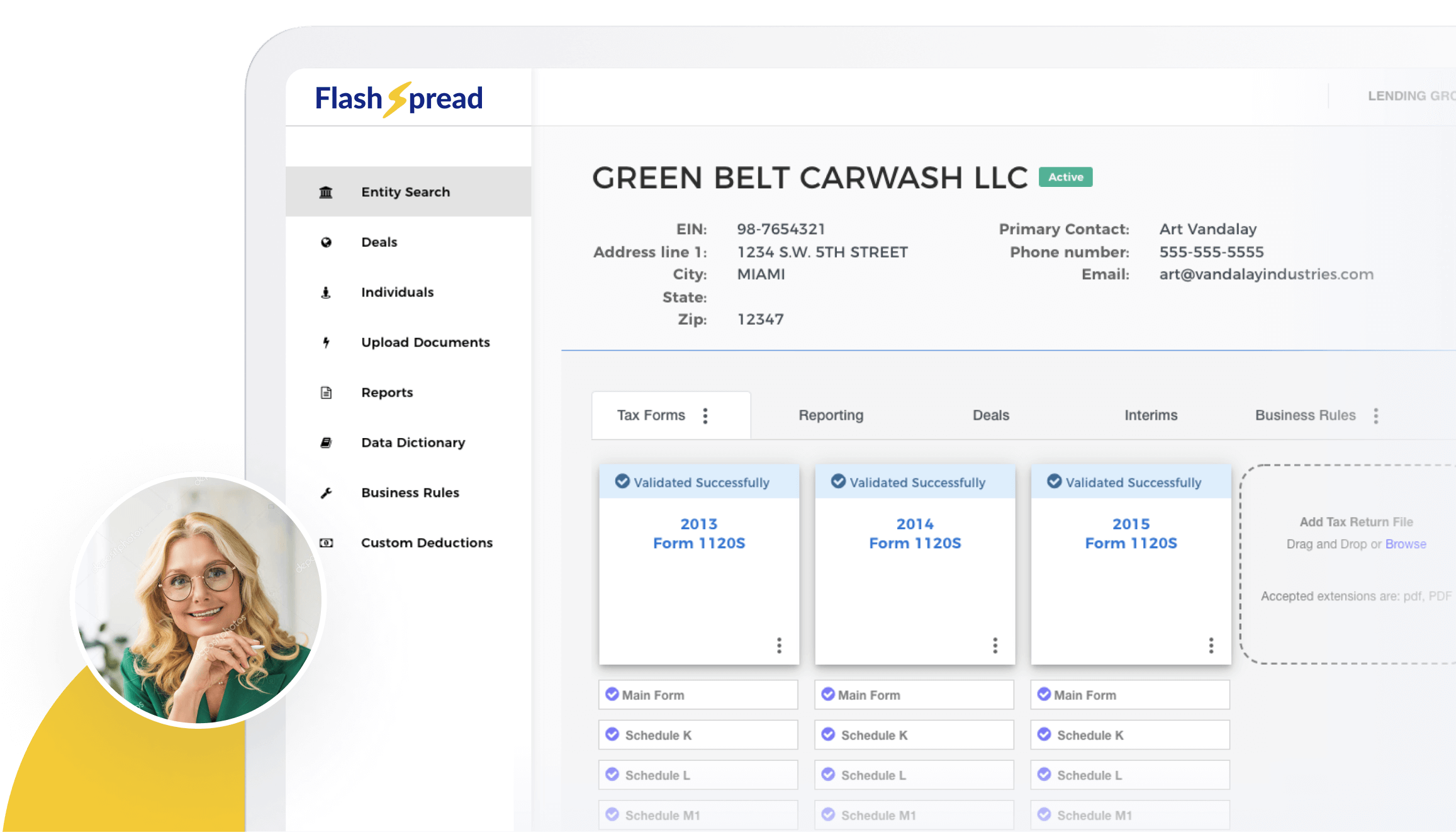
Automated financial statement spreading takes an incredible burden off of human employees as it doesn’t require manual data entry. But processing that data and finding what you need? That is not always as easy. If you already use automated systems to spread your data, then integrating automatic processing is a great next step. Improved artificial intelligence has increased the variety of documents that can be analyzed using automation.
However, all documents are not created equal. To have successful automated data extraction, you need to recognize the issues that arise from, for example, handwriting versus print, structured versus unstructured documents and other problems. Then, you need to program for different parameters, goals, and desired outcomes. Let’s look at the 7 most common types of data extraction, how they work, and where they can be applied.
Table of Contents
1) Static Zones
Imagine you have a big stack of papers, but these are special papers with important information that you need to find. It would take a long time to look through every paper to find what you need, right? Well, what if there was a magic tool that could help you find the information you needed quickly and easily?
Lucky for us, there is such a tool! It’s called “static zones” and it works best on highly-structured forms with layouts that remain consistent over time. These kinds of forms include 1099, government annuity, and Social Security benefit statements.
With static zones, you can tell the tool where to look on the paper for the information you need. You simply draw a box or a circle around the important parts and the tool does the rest! It’s like magic!
Static zones help you save time and effort. It’s perfect for when you have many forms to go through and you need to find important information quickly. By using static zones, you can find the information you need in no time and without getting tired from looking through many papers.
So, next time you need to find important information on highly-structured forms like 1099, government annuity, or Social Security benefit statements, remember to use the magic of static zones!
2) Dynamic Zones
As you use static zones to extract data from highly-structured forms, you may sometimes encounter a slight shift in the defined coordinates. This can happen for a number of reasons, such as a poor file capture, such as a blurry fax or incomplete scanned image. Even small document updates made over time can cause these subtle changes to occur.
For example, popular forms like the W-9 and 1040 have gone through revisions over the years, leading to changes in their layouts. When these changes occur, the defined coordinates may no longer match up with the new layout of the form. This can be frustrating and time-consuming, especially when you have many forms to process.
Luckily, there’s a solution to this problem: dynamic zones. Unlike static zones, which rely on fixed coordinates to extract data, dynamic zones are designed to account for adjustments in the layout of a form over time. This means that even when small changes occur, dynamic zones can still accurately search for and extract the data you need.
So, if you ever encounter a shift in the defined coordinates of your static zones, don’t worry. Just remember the power of dynamic zones and the flexibility they offer when working with highly-structured forms that undergo changes over time. With dynamic zones, you can confidently extract data from even the most complex forms and documents.
3) Dynamic Tables
If you’re looking to extract table data from highly-structured forms, the dynamic table technique is a powerful tool at your disposal. With this technique, you can pre-define columns and rows that the system will use to search for the necessary data.
The beauty of the dynamic table technique lies in its ability to accurately locate data at the intersection of certain columns and rows, even if their locations change over time. This means that you don’t have to worry about updates or changes to the form layout. The system will still be able to find and extract the data you need.
For example, imagine that you’re dealing with a form that has a table containing important information. With the dynamic table technique, you can simply pre-define the columns and rows you want the system to search. Even if the form layout changes, with columns or rows switching locations, the system will still be able to accurately locate and extract the necessary data.
This makes the dynamic table technique a versatile and reliable tool for data extraction. Whether you’re working with financial documents, government forms, or any other highly-structured forms with tables, the dynamic table technique can help you extract data with ease and accuracy.
4) Key-Value Pairs (KVP)
As you move into more advanced data extraction techniques, you’ll come across Key-Value Pairs, or KVPs. This technique is especially useful when dealing with forms that have undefined layouts, as it allows you to associate specific values with keywords, such as “last name” and “Smith” or “Jones.”
Subscribe to BeSmartee 's Digital Mortgage Blog to receive:
- Mortgage Industry Insights
- Security & Compliance Updates
- Q&A's Featuring Mortgage & Technology Experts
With KVPs, you can also define other key-value pairs, like “birth date” or “D.O.B.”, and the corresponding value of the client’s date of birth. Once you set the parameters, your system can then search for the specified pairs.
But the power of KVPs goes even further. Advanced machine learning systems can automatically define all the search limits and include all possible keyword variations, such as “birth date,” “DOB,” and “D.O.B..” This means that you don’t have to manually define every possible variation of a keyword or value, making the extraction process much more efficient.
For lenders, KVPs are a game-changer when dealing with forms that have undefined layouts, as they can help streamline the data extraction process and ensure accuracy. So whether you’re dealing with financial documents, government forms, or any other type of form, KVPs are an advanced data extraction technique that can help you get the job done with ease and precision.
5) Navigational Key-Value Pairs
Sometimes, the key and value pair you need to extract won’t be conveniently located side-by-side on a page. These are called navigational key-value pairs, and they can pose a challenge for data extraction systems.
But if you’re using an advanced extraction system, there’s no need to worry. These systems are designed to identify split pairs by locating the key and then navigating to the corresponding value, even if it’s located within a block of text.
This advanced technique requires a high degree of precision and accuracy, as the system must be able to recognize the key in a variety of contexts and then navigate to the correct value. But when done correctly, it can make the data extraction process much more efficient, even when dealing with complex or poorly structured documents.
So whether you’re working with financial reports, legal documents, or any other type of form, a system that can handle navigational key-value pairs is an essential tool for accurate and efficient data extraction.
6) Non-Contextual Entities
Entity extraction is a sophisticated technique used in data extraction that allows systems to identify and extract specific entities or information from unstructured or semi-structured documents. This technique is more complex than KVP because it relies on predefined sets of data to locate and extract information, instead of using key-value pairs or other methods.
Non-contextual entity extraction is particularly useful for documents that lack a defined structure, such as freeform documents like legal contracts or property descriptions. These types of documents are more difficult to extract data from because there are no set fields or columns to locate data in.
Instead, entity extraction relies on predefined sets of data to search for specific entities, such as social security numbers, names, addresses, or other important data. The system can locate the entities using rules-based or machine learning algorithms that have been trained to recognize the relevant patterns in the text.
For instance, a system can extract all the Social Security numbers in a document as long as the entity is defined as a 9-digit number or its XXX-XX-XXXX format. This technique helps to ensure that important data is not missed, even in documents that are difficult to extract information from.
7) Contextual Entities
Contextual entity extraction is an advanced data extraction technique that relies on machine learning systems to identify and extract entities based on context. Unlike other extraction methods, contextual entity extraction does not require pre-defined sets of data or patterns to identify entities. Instead, it analyzes the document’s contents and formulates its own rules to find the required entities.
This sophisticated technique is used in situations where documents lack structure, such as legal contracts or invoices, and require deeper analysis to extract important data. Contextual entity extraction is highly accurate because it uses contextual clues and machine learning to infer the meaning of data, ensuring that the extracted results are correct. After the data is extracted, it can be compared to other recordkeeping systems to ensure that it matches and is properly recorded.
Data Extraction Roundup
Data extraction is continuously evolving, with new techniques and formulas coming into use. Adding data extraction to your existing financial data automation program can save you time and money, streamline your customer service and avoid human error.
For more information about financial data automation and how FlashSpread can help, contact us.